
In this tutorial we will explore how to extract images from PDF files using Python.
Table of Contents
Introduction
Extracting images from PDF files is a very common task that’s often performed when working with different reports.
It’s a tedious task if you do it manually for every file using the available software and online tools.
In this tutorial we will explore how to extract images from PDF files using Python.
To continue following this tutorial we will need the following Python libraries: PyMuPDF and Pillow.
If you don’t have them installed, please open “Command Prompt” (on Windows) and install them using the following code:
pip install PyMuPDF
pip install Pillow
Sample PDF file
Here is the PDF file we will use in this tutorial:
This PDF file will reside in the same folder as the main.py with our code.
We will also need to create an empty folder images to save the extracted images, so the project directory structure should look like this:
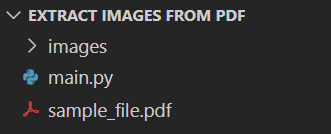
Extract images from PDF using Python
Let’s start with importing the required dependencies:
#Import required dependencies
import fitz
import os
from PIL import Image
Define the path to PDF file:
#Define path to PDF file
file_path = 'sample_file.pdf'
Open the file using fitz module and extract all images information:
#Open PDF file
pdf_file = fitz.open(file_path)
#Calculate number of pages in PDF file
page_nums = len(pdf_file)
#Create empty list to store images information
images_list = []
#Extract all images information from each page
for page_num in range(page_nums):
page_content = pdf_file[page_num]
images_list.extend(page_content.get_images())
Now, let’s take a look at the images information we extracted:
print(images_list)
And you should get:
[(9, 0, 640, 491, 8, 'DeviceRGB', '', 'Image9', 'DCTDecode'),
(10, 0, 640, 427, 8, 'DeviceRGB', '', 'Image10', 'DCTDecode'),
(13, 0, 640, 427, 8, 'DeviceRGB', '', 'Image13', 'DCTDecode')]where each tuple represents the following:
(xref, smask, width, height, bpc, colorspace, alt. colorspace, name, filter)Now let’s add some error handling code in case the PDF file we work with has no images:
#Raise error if PDF has no images
if len(images_list)==0:
raise ValueError(f'No images found in {file_path}')
After we have extracted the images information from the PDF file, we can extract the actual images and save them on the computer:
#Save all the extracted images
for i, image in enumerate(images_list, start=1):
#Extract the image object number
xref = image[0]
#Extract image
base_image = pdf_file.extract_image(xref)
#Store image bytes
image_bytes = base_image['image']
#Store image extension
image_ext = base_image['ext']
#Generate image file name
image_name = str(i) + '.' + image_ext
#Save image
with open(os.path.join(images_path, image_name) , 'wb') as image_file:
image_file.write(image_bytes)
image_file.close()
After running the code, you should see the extracted images appear in the images folder:
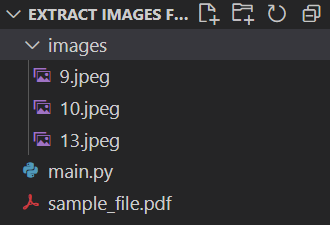
Complete code
#Import required dependencies
import fitz
import os
from PIL import Image
#Define path to PDF file
file_path = 'sample_file.pdf'
#Define path for saved images
images_path = 'images/'
#Open PDF file
pdf_file = fitz.open(file_path)
#Get the number of pages in PDF file
page_nums = len(pdf_file)
#Create empty list to store images information
images_list = []
#Extract all images information from each page
for page_num in range(page_nums):
page_content = pdf_file[page_num]
images_list.extend(page_content.get_images())
#Raise error if PDF has no images
if len(images_list)==0:
raise ValueError(f'No images found in {file_path}')
#Save all the extracted images
for i, img in enumerate(images_list, start=1):
#Extract the image object number
xref = img[0]
#Extract image
base_image = pdf_file.extract_image(xref)
#Store image bytes
image_bytes = base_image['image']
#Store image extension
image_ext = base_image['ext']
#Generate image file name
image_name = str(i) + '.' + image_ext
#Save image
with open(os.path.join(images_path, image_name) , 'wb') as image_file:
image_file.write(image_bytes)
image_file.close()
Conclusion
In this article we explored how to extract images from PDF files using Python and PyMuPDF.
Feel free to leave comments below if you have any questions or have suggestions for some edits and check out more of my Python Programming tutorials.
Is it possible to extract text and images from a pdf and then save them in other pdf on same positions using python?. Thanks and Regards
I would assume it’s possible but I haven’t tried saving extracted images in another PDF in the same positions in the file.