
In this tutorial we will discuss how to extract table from PDF files using Python.
Table of contents
- Introduction
- Sample PDF files
- Extract single table from a single page of PDF using Python
- Extract multiple tables from a single page of PDF using Python
- Extract all tables from PDF using Python
- Conclusion
Introduction
When reading research papers or working through some technical guides, we often obtain then in PDF format.
They carry a lot of useful information and the reader may be particularly interested in some tables with datasets or findings and results of research papers.
However, we all face a difficulty of easily extracting those tables to Excel or to DataFrames.
Thanks to Python and some of its amazing libraries, you can now extract these tables with a few lines of code!
To continue following this tutorial we will need the following Python library: tabula-py.
If you don’t have it installed, please open “Command Prompt” (on Windows) and install it using the following code:
pip install tabula-py
tabula-py is a Python wrapper for tabula-java, so you will also need Java installed on your computer. You can download it here.
Sample PDF files
Now that we have the requirements installed, let’s find a few sample PDF files from which we will be extracting the tables.
This file is used solely for the purposes of the code examples:
Now let’s dive into the code!
Extract single table from single page of PDF using Python
In this section we will work with the file mentioned above. If you took a look, you can see that it has a total of 3 tables on 2 pages: 1 table on page 1 and 2 tables on page 2.
Suppose you are interested in extracting the first table which looks like this:
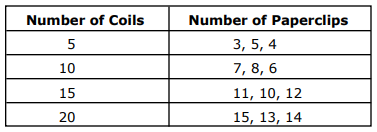
We know that it is on the first page of the PDF file. Now we can extract it to CSV or DataFrame using Python:
Method 1:
Step 1: Import library and define file path
import tabula
pdf_path = "https://sedl.org/afterschool/toolkits/science/pdf/ast_sci_data_tables_sample.pdf"
Step 2: Extract table from PDF file
dfs = tabula.read_pdf(pdf_path, pages='1')
The above code reads the first page of the PDF file, searching for tables, and appends each table as a DataFrame into a list of DataFrames dfs.
Here we expected only a single table, therefore the length of the dfs list should be 1:
print(len(dfs))
And it should return:
1You can also validate the result by displaying the contents of the first element in the list:
print(dfs[0])
And get:
Number of Coils Number of Paperclips
0 5 3, 5, 4
1 10 7, 8, 6
2 15 11, 10, 12
3 20 15, 13, 14Step 3: Write dataframe to CSV file
Simply write the DataFrame to CSV in the same directory:
dfs[0].to_csv("first_table.csv")
Method 2:
This method will produce the same result, and rather than going step-by-step, the library provides a one-line solution:
import tabula
tabula.convert_into(pdf_path, "first_table.csv", output_format="csv", pages='1')
Important:
Both of the above methods are easy to use when you are sure that there is only one table on a particular page.
In the next section we will explore how to adjust the code when working with multiple tables.
Extract multiple tables from a single page of PDF using Python
Recall that the PDF file has 2 tables on page 2.
We want to extract the tables below:
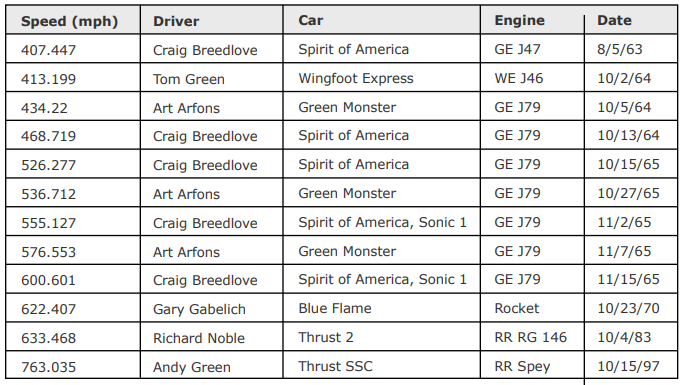
and
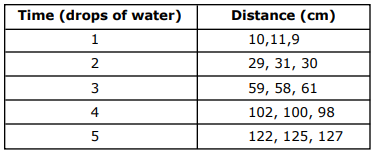
Using Method 1 from the previous section, we can extract each table as a DataFrame and create a list of DataFrames:
import tabula
pdf_path = "https://sedl.org/afterschool/toolkits/science/pdf/ast_sci_data_tables_sample.pdf"
dfs = tabula.read_pdf(pdf_path, pages='2')
Notice that in this case we set pages=’2′, since we are extracting tables from page 2 of the PDF file.
Check that the list contains two DataFrames:
print(len(dfs))
And it should return:
2Now that the list contains more than one DataFrame, each can be extracted in a separated CSV file using a for loop:
for i in range(len(dfs)):
dfs[i].to_csv(f"table_{i}.csv")
and you should get two CSV files: table_0.csv and table_1.csv.
Note: if you try to use Method 2 described in the previous section, it will extract the 2 tables into a single worksheet in the CSV file and you would need to break it up into two worksheets manually.
Extract all tables from PDF using Python
In the above sections we focused on extracting tables from a given single page (page 1 or page 2). Now what do we do if we simply want to get all of the tables from the PDF file into different CSV files?
It is easily solvable with tabula-py library. The code is almost identical to the previous part. The only change we would need to do is set pages=’all’, so the code extracts all of the tables it finds as DataFrames and creates a list with them:
import tabula
pdf_path = "https://sedl.org/afterschool/toolkits/science/pdf/ast_sci_data_tables_sample.pdf"
dfs = tabula.read_pdf(pdf_path, pages='all')
Check that the list contains all three DataFrames:
print(len(dfs))
And it should return:
3Now that the list contains more than one DataFrame, each can be extracted in a separated CSV file using a for loop:
for i in range(len(dfs)):
dfs[i].to_csv(f"table_{i}.csv")
Conclusion
In this article we discussed how to extract table from PDF files using tabula-py library.
Feel free to leave comments below if you have any questions or have suggestions for some edits and check out more of my Python for PDF tutorials.