In this tutorial we will discuss how to extract tables from HTML files using Python.
Table of contents
- Introduction
- Sample HTML file
- Extract table from HTML file using Python
- Extract table from Webpage using Python
- Convert HTML Table to CSV using Python
- Conclusion
Introduction
Extracting tables from HTML files and Webpages is often useful when you want to save some data from tables you found on a website (or in HTML file).
It can be a very tedious and time consuming task if you try to copy and paste the data manually, as well as it will be difficult to maintain the formatting and structure of each table.
Python provides several libraries for extracting data from HTML files and webpages, which can help you automate this task.
To continue following this tutorial we will need the following Python libraries: pandas, html5lib and lxml.
If you don’t have them installed, please open “Command Prompt” (on Windows) and install it using the following code:
pip install pandas
pip install html5lib
pip install lxml
Sample HTML File
Now that we have the requirements installed, let’s find a sample HTML files from which we will be extracting the tables.
Here is the file I created in one of my previous tutorials:
which contains the following code:
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>student_id</th>
<th>first_name</th>
<th>last_name</th>
<th>grade</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>1221</td>
<td>John</td>
<td>Smith</td>
<td>86</td>
</tr>
<tr>
<th>1</th>
<td>1222</td>
<td>Erica</td>
<td>Write</td>
<td>92</td>
</tr>
<tr>
<th>2</th>
<td>1223</td>
<td>Will</td>
<td>Erickson</td>
<td>74</td>
</tr>
<tr>
<th>3</th>
<td>1224</td>
<td>Madeline</td>
<td>Berg</td>
<td>82</td>
</tr>
<tr>
<th>4</th>
<td>1225</td>
<td>Mike</td>
<td>Ellis</td>
<td>79</td>
</tr>
</tbody>
</table>Opening this file with your default browser should show the data in a table format:
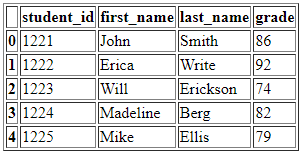
Place the HTML file in the same directory as the file with the Python code.
Note: this is a very simple file that only contains HTML code for the table. However, the approach and code shown in this tutorial can be used on more complex files with multiple tables and other content.
Extract table from HTML file using Python
In the first example we will discuss how to extract tables from HTML files using Python.
We begin with importing the required dependency and defining the path to the HTML file:
#Import the required dependency
import pandas as pd
#Define path to HTML file
html_path = 'grades.html'
Next, using Pandas .read_html() function we will read tables from the HTML file into a list of DataFrames and print them:
#Read tables from HTML file
tables = pd.read_html(html_path)
#Print tables separated by empty rows
for table in tables:
print(table, '\n\n')
and you should get:
Unnamed: 0 student_id first_name last_name grade
0 0 1221 John Smith 86
1 1 1222 Erica Write 92
2 2 1223 Will Erickson 74
3 3 1224 Madeline Berg 82
4 4 1225 Mike Ellis 79
If you need to save the tables, you can convert them to CSV.
Note: if your HTML file contains multiple tables, all of them will be printed.
Extract Table from Webpage using Python
If the tables you wand to extract are on a particular webpage, you can extract them using Python.
We begin with importing the required dependencies and defining the URL of the Webpage:
#Import the required dependencies
import pandas as pd
from urllib.request import Request, urlopen
#Define URL of the Webpage
url = 'https://pyshark.com/jaccard-similarity-and-jaccard-distance-in-python/'
In this example we will extract tables from one of my articles about Jaccard similarity and Jaccard distance in Python.
This article contains 3 tables that we are going to extract.
Next, using the Urllib library we will extract the HTML content from the Webpage:
#Create an abstraction of URL request
request = Request(url)
#Add headers to the request
request.add_header('user-agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36')
#Open the URL
page = urlopen(request)
#Read HTML content
html_content = page.read()
Next, using Pandas .read_html() function we will read tables from the HTML content of the Webpage into a list of DataFrames and print them:
#Read tables from HTML file
tables = pd.read_html(html_content)
#Print tables
for table in tables:
print(table, '\n\n')
and you should get:
0 1 2 3 4 5 6
0 NaN Apple Tomato Eggs Milk Coffee Sugar
1 A 1 0 0 1 1 1
2 B 0 0 1 1 1 0
0 1 2
0 NaN Count Explanation
1 \(M_{11}\) 2 Both customers bought coffee and milk
2 \(M_{01}\) 1 Customer A didn’t buy eggs, whereas...
3 \(M_{10}\) 2 Customer B didn’t buy apple and sugar...
4 \(M_{00}\) 1 Neither of customers bought tomato
0 1 2 3 4 5 6
0 NaN Apple Tomato Eggs Milk Coffee Sugar
1 A 1 0 0 1 1 1
2 B 0 0 1 1 1 0If you need to save the tables, you can convert them to CSV.
Convert HTML Table to CSV using Python
In the previous sections we explored how to extract tables from HTML files and Webpages, and in this section we will explore how to convert the extracted tables to CSV using Python.
If you want to save your tables as CSV files instead of printing them, you will need to change the part of the code that iterates over tables and prints them out.
Using Python enumerate() function, we will keep track of the index of each table and create a CSV file with each table with index as a part of the file name:
#Save tables
for i, table in enumerate(tables, start=1):
file_name = f'table_{i}.csv'
table.to_csv(file_name)
and you should see the CSV files appear in the same directory as your file with Python code.
Conclusion
In this article we explored how to extract tables from HTML files and Webpages using Python, pandas and urllib.
Feel free to leave comments below if you have any questions or have suggestions for some edits and check out more of my Python Programming tutorials.